Navigation
- Intro to Version Control Systems
- Local Repositories
- Git Branching
- Example: Local Repository
- Other Git Features
- Remote Repositories
- Example: Remote Repository
- Conclusion
- Advanced Git Features
A. Intro to Version Control Systems
Version control systems are tools to keep track of changes to files over time.
Version control allows you to view or revert back to previous iterations of
files. Some aspects of version control are actually built into commonly used
applications. Think of the undo command or how you can see the revision history
of a Google document.
In the context of coding, version control systems can track the history of code revisions, from the current state of the code all the way till it was first tracked. This allows users to reference older versions of their work and share code changes with other people, like fellow developers.
Version control has become a backbone of software development and collaboration in industry. In this class, we will be using Git. Git has excellent documentation so we highly encourage those who are interested to read more about what will be summarized in the rest of this guide.
Intro to Git
Git it a distributed version control system as opposed to a centralized version control system. This means that every developer's working copy of the code is a complete repository that can stand apart from a shared, centralized server. This concept leads to our ability to use Git locally on our own computers.
The lab computers already have Git installed on the command line. If you would like to set Git up on your own computer, you can either choose between command line Git or a Git GUI (Graphical User Interface). For the purposes of this lab, we will be using command line Git.
If you would like help setting up Git on your own computer, follow this guide on setting up Git.
B. Local Repositories
Initializing Local Repositories
Let's first start off with the local repository. A repository stores files as well as the history of changes to those files. In order to begin, you must initialize a Git repository by typing the following command into your terminal while in the directory you wish to make it a local repository.
$ git initWhen you initialize a Git repository, Git actually creates a .git subdirectory
that cannot be seen as a default for most operating systems. But it's there.
The UNIX command ls -la will list all directories, including your .git
directory, so you can use this command to check that your repo has been
initialized properly.
Tracked vs. Untracked Files
Git repos start off not tracking any files. In order to save the revision history of a file, you need to track it. The Git documentation has an excellent section on recording changes. An image from that section is placed here for your convenience:
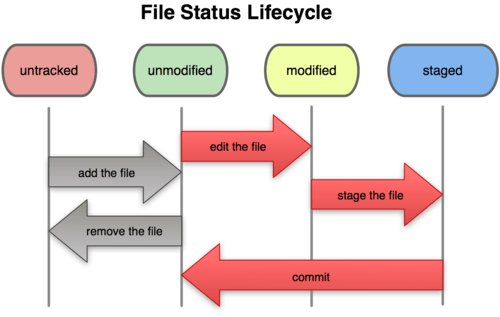
As this figure shows, files fall into two main categories:
- untracked files: These files have either never been tracked or were removed from tracking. Git is not maintaining history for these files.
tracked files: These files have been added to the Git repository and can be in various stages of modification: unmodified, modified, or staged.
- An unmodified file is one that has had no new changes since the last version of the files was added to the Git repo.
- A modified file is one that is different from the last one Git has saved.
- A staged file is one that a user has designated as part of a future commit.
The following Git command allows you see the status of each file:
$ git statusThe git status command is extremely useful for determining the exact status of
each file in your repository. If you are confused about what has changed and
what needs to be committed, it can remind you of what to do next.
Staging & Committing
A commit is a specific snapshot of your working directory at a particular time. Users must specify what exactly composes the snapshot by staging files.
This command lets you stage a file (called FILE). Before staging, a file can
be untracked or tracked & modified. After staging and committing it, it will be
a tracked file.
$ git add FILEOnce you have staged all the files you would like to include in your snapshot, you can commit them as one block with a message.
$ git commit -m MESSAGEYour message should be descriptive and explain what changes your commit makes to your code. You may want to quickly describe bug fixes, implemented classes, etc. so that your messages are helpful later when looking through your commit log.
In order to see previous commits, you can use the log command:
$ git logThe Git reference guide has a helpful section on viewing commit history
and filtering log results when searching for particular commits. It might
also be worth checking out gitk, which is a GUI prompted by the command line.
As a side note on development workflow, it is a good idea to commit your code as often as possible. Whenever you make significant (or even minor) changes to your code, make a commit. If you are trying something out that you might not stick with, commit it (perhaps to a different branch, which will be explained below).
Rule of Thumb: If you commit, you can always revert your code or change it. However, if you don't commit, you won't be able to get old versions back. So commit often!
Undoing Changes
The Git reference has a great section on undoing things. Please note that while Git revolves around the concept of history, it is possible to lose your work if you revert with some of these undo commands. Thus, be careful and read about the effects of your changes before undoing your work.
Unstage a file that you haven't yet committed:
$ git reset HEAD [file]This will take the file's status back to modified, leaving changes intact. Don't worry about this command undoing any work.
Why might we need to use this command? Let's say you accidentally started tracking a file that you didn't want to track. (.class files, for instance.) Or you were doing some work and thought you would commit but no longer want to commit the file.
Amend latest commit (changing commit message or add forgotten files):
$ git add [forgotten-file] $ git commit --amendPlease note that this new amended commit will replace the previous commit.
Revert a file to its state at the time of the most recent commit:
$ git checkout -- [file]This next command is useful if you would like to actually undo your work. Let's say that you have modified a certain
filesince committing previously, but you would like your file back to how it was before your modifications.Note: This command is potentially quite dangerous because any changes you made to the file since your last commit will be removed. Use this with caution!
C. Git Branching

Every command that we've covered so far was working with the default branch.
This branch is conventionally called the master branch. However, there are
cases when you may want to create branches in your code.
Branches allow you to keep track of multiple different versions of your work simultaneously. One way to think of branches are as alternate dimensions. Perhaps one branch is the result of choosing to use a linked list while another branch is the result of choosing to use an array.

Reasons for Branching
Here are some cases when it may be a good idea to branch.
- You may want to make a dramatic change to your existing code (called refactoring) but it will break other parts of your project. But you want to be able to simultaneously work on other parts or you have partners, and you don't want to break the code for them.
- You want to start working on a new part of the project, but you aren't sure yet if your changes will work and make it to the final product.
- You are working with partners and don't want to mix up your current work with theirs, even if you want to bring your work together later in the future.
Creating a branch will let you keep track of multiple different versions of your code, and you can easily switch between versions and merge branches together once you've finished working on a section and want it to join the rest of your code.
An Example Scenario
For example, let's say that you've finished half of a project so far. There is
a difficult part still left to do, and you're not sure how to do it. Perhaps
you have three different ideas for how to do it, and you're not sure which
will work. At this point, it might be a good idea to create a branch off of
master and try out your first idea.
- If your code works, you can merge the branch back to your main code (on the
masterbranch) and submit your project. - If your code doesn't work, don't worry about reverting your code and having to
manipulate Git history. You can simply switch back to
master, which won't have any of your changes, create another branch, and try out your second idea.
This can continue till you figure out the best way to write you code, and you
only need to merge the branches that work back into master in the end.
The Git reference has a section on branching and merging with some figures of how branches are represented in Git's underlying data structure. It turns out that Git keeps track of commit history as a graph with branch pointers and commits as nodes within the graph. (Hence the tree-related terminology.)
Creating, Deleting, & Switching Branches
A special branch pointer called the HEAD references the branch you currently
have as your working directory. Branching instructions modify branches and
change what your HEAD points to so that you see a different version of your
files.
The following command will create a branch off of your current branch.
$ git branch [new-branch-name]This command lets you switch from one branch to another by changing which branch your
HEADpointer references.$ git checkout [destination-branch]By default, your initial branch is called
master. It is advised that you stick with this convention. Every other branch, however, can be named whatever you'd like. It's generally a good idea to call your branch something descriptive likefixing-ai-heuristicsso that you can remember what commits it contains.You can combine the previous two commands on creating a new branch and then checking it out with this single command:
$ git checkout -b [new-branch-name]You can delete branches with the following command:
$ git branch -d [branch-to-delete]You can easily figure out which branch you are on with this command:
$ git branch -vMore particular, the
-vflag will list the last commit on each branch as well.
Merging
There are often times when you'd like to merge one branch into another. For
example, let's say that you like the work you've done on fixing-ai-heuristics.
Your AI is now super-boss, and you'd like your master branch to see the
commits you've made on fixing-ai-heuristics and delete the fixing-ai-heuristics
branch.

In this case, you should checkout the master branch and merge
fixing-ai-heuristics into master.
$ git checkout master
$ git merge fixing-ai-heuristicsThis merge command will create a new commit that joins the two branches
together and change each branch's pointer to reference this new commit. While
most commits have only one parent commit, this new merge commit has two parent
commits. The commit on the master branch is called its first parent and
the commit on the fixing-ai-heuristics branch is called its second parent.

Merge Conflicts
It may happen that two branches you are trying to merge have conflicting information. This can occur if commits on the two branches changed the same files. Git is sophisticated enough to resolve many changes, even when they occur in the same file (though distinct places).
However, there are times that conflicts cannot be resolved by Git because changes impact the same methods/lines of code. In these cases, it will present both changes from the different branches to you as a merge conflict.
Resolving Merge Conflicts
Git will tell you which files have conflicts. You need to open the files that have conflicts and resolve them manually. After doing this, you must commit to complete the merge of the two branches.
The files with conflicts will contain segments that look something like this:
<<<<<<< HEAD
for (int i = 0; i < results.length; i++) {
println(results[i]);
println("FIX ME!");
}
=======
int[] final = int[results.length];
for (int i = 0; i < results.length - 1; i++) {
final[i] = results[i] + 1;
println(final[i]);
}
>>>>>>> fixing-ai-heuristicsBasically, you'll see two segments with similar pieces of code:
- The top code snippet is from the branch you originally had checked out when
you ran the
mergecommand. It's calledHEADbecause theHEADpointer was referencing this branch at the time of themerge. Continuing our example above, this code would be from themasterbranch. - The bottom code snippet is from the branch you were merging into your checked
out branch. This is why it shows that the code is from
fixing-ai-heuristics.
Basically, you'll need to go through all marked sections and pick which snippet of code you'd like to keep.
In the previous example, I like the bottom piece of code better because I just fixed the AI while the top piece still prints "FIX ME!" Thus, I will delete the top segment as well as the extraneous lines to get this:
int[] final = int[results.length];
for (int i = 0; i < results.length - 1; i++) {
final[i] = results[i] + 1;
println(final[i]);
}Random Note: I have no idea how this code supposedly fixes the AI heuristics. Don't use it for your project! It is useless, I tell you. Useless!
Doing this for all segments demarcated by conflict-resolution markers resolves your conflict. After doing this for all conflicting files, you can commit. This will complete your merge.
D. Example: Local Repository
You're now ready to start using Git! Follow along as I work through a simple example. This example may seem a bit contrived, but it will hopefully help you become more familiar with a Git workflow.
Also, if you'd like more of a challenge, read the direction for each step and guess what the command should be before looking at my Terminal window.
And yes, my lovely computer is named wellington. Quite the classy name,
wouldn't you say?
Initialize a Git repository called
learning-git.
Add a file called
HELLO.txt.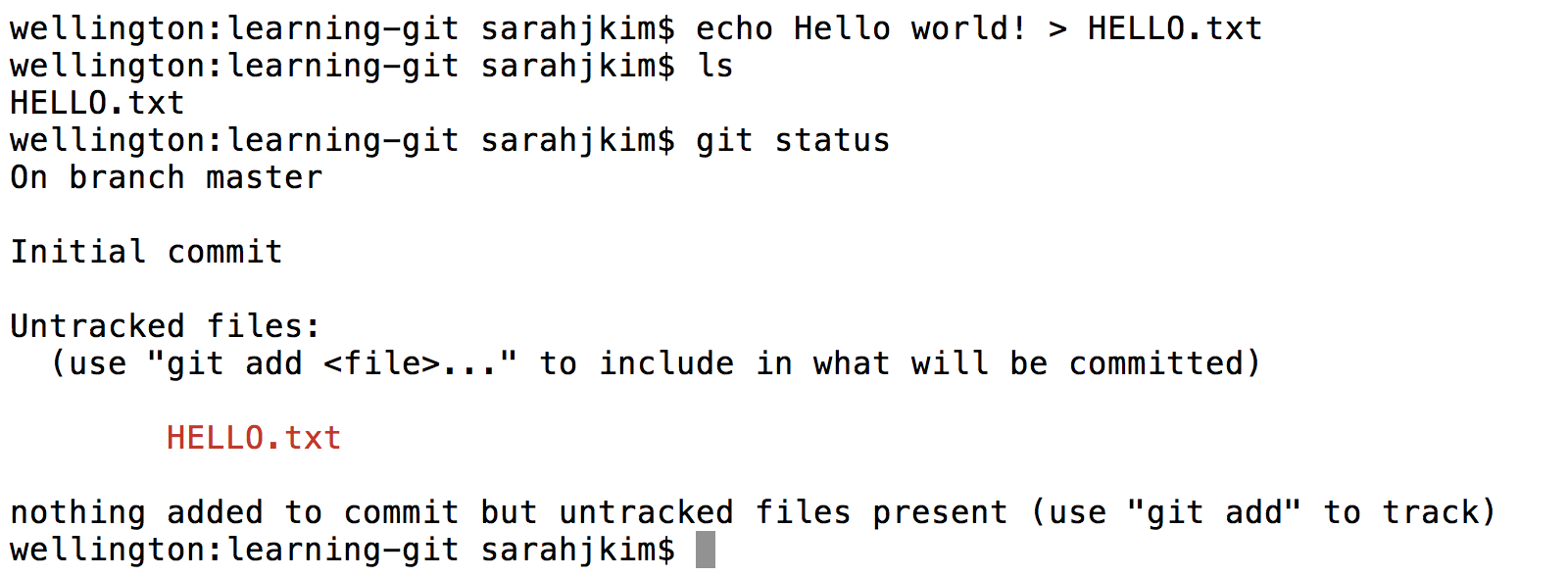
Suppose we want to save the state of this file in git. First we stage it:
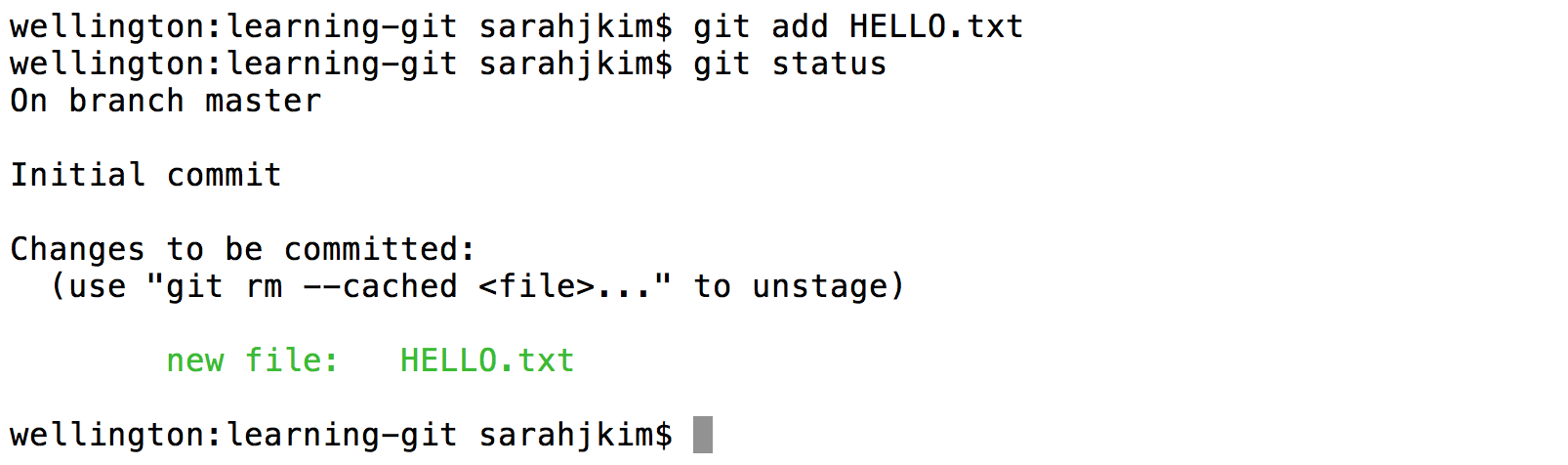
Now that we have staged
HELLO.txt, it will be included in our commit. Commit the file with a message of your choice.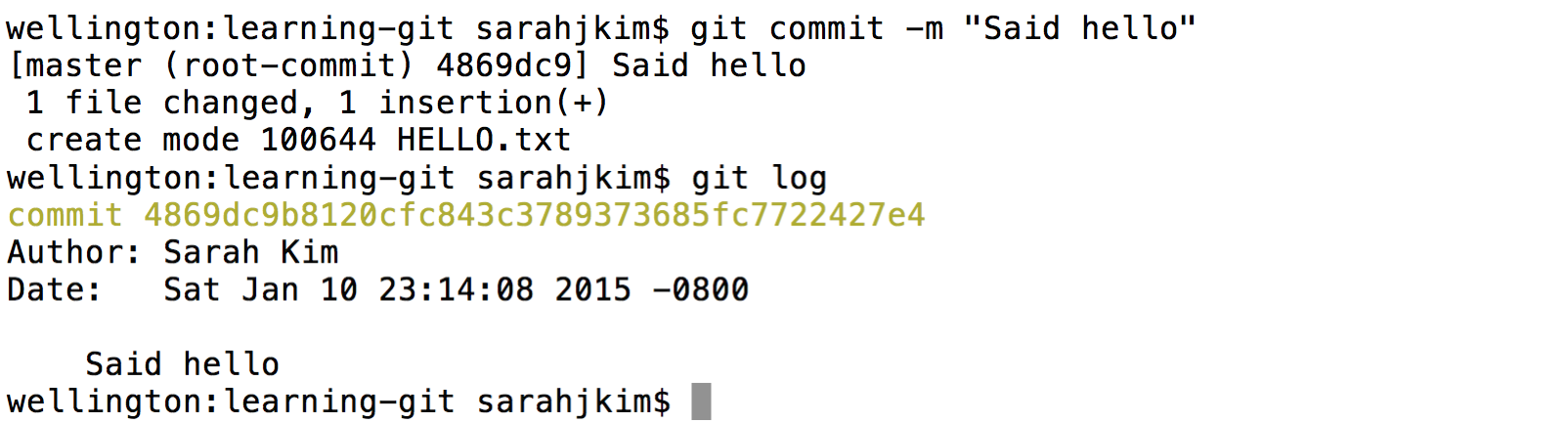
Let's update our
HELLO.txt. Here I used a text editor called vim to add some text to the file. You can use any text editor of your choice.
If we want to save the change we made in git, first we'll have to stage it. Stage it with the
addcommand. Then, suppose we decide we no longer like the change we made, and we don't want to save it in Git. Unstage the file with theresetcommand.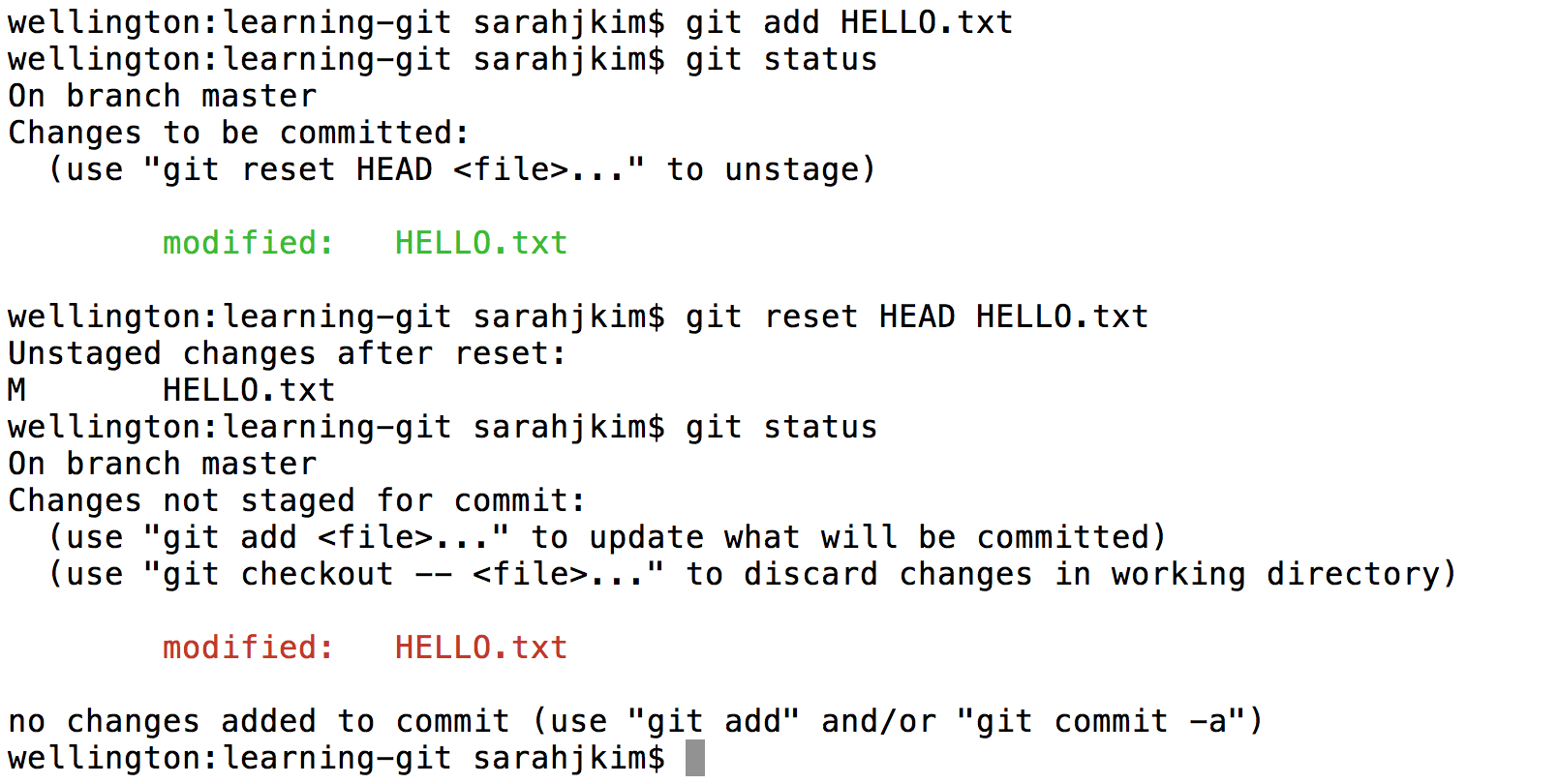
Now suppose we dislike the changes we made so much, we want to return the file to its state the last time we committed it — that is, before we added the extra lines. Discard your changes to
HELLO.txtsince your first commit with thecheckoutcommand.
Now let's practice using a branch. Create a branch named
bye-branchand switch to it.
Change
HELLO.txtby adding "Bye world!" on a new line and commit this change. Note that this commit is for the currentbye-branchonly.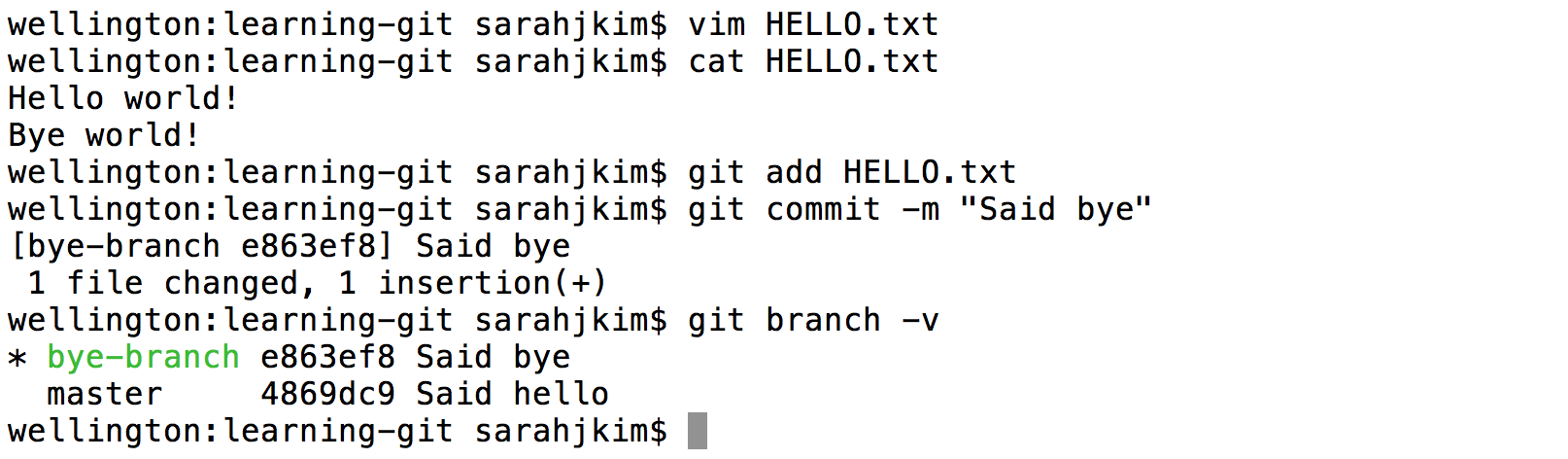
Suppose now we decide we like the changes, and we want to merge them into our
masterbranch.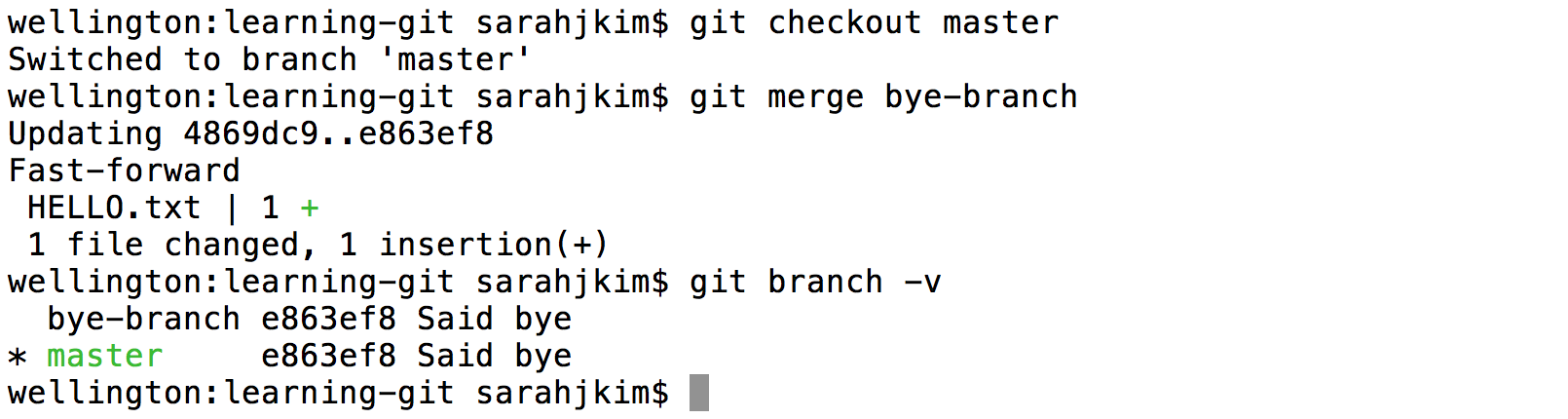
Now that we've merge
bye-branchintomaster, we can remove it. Themasterbranch will still have access to the commits that were once created inbye-branch.
E. Other Git Features
There are tons of other cool Git commands. Unfortunately, we need to continue on to discuss remote repositories. Thus, this segment will just list some other interesting features that you are encouraged to explore in your own time:
-
Stashing allows you to save your changes onto a stack without making a more permanent commit. It is equivalent to picking up your work-in-progress and placing it in a box to get back to later. In the meantime, your desk is now clean.
Why might you want to use this?
- Your files may be in a disorganized state, and you don't want to commit yet, but you also don't want to get rid of your changes.
- You modified multiple files, but you dislike your changes and
you would just like to get things back to how they were after your most
recent commit. Then you can
stashyour code and then drop that stash rather than having to manually revert multiple files. (Be careful with this usage!) - You modified files but accidentally modified them on the wrong branch.
Then you can
stashyour changes, switch branches, and unstash your changes so that they are all in the new branch.
-
Let's say you want to do more than change your last commit or drop changes to your files before your most recent commit. What if you want to do something crazy like rewrite history? You can change multiple commit messages, splits one commits into two, and reorder commits.
-
Rebasing changes the parent commit of a specific commit. In doing this, it changes the commits so that it is no longer the same.
Rebasecan be used as an alternative tomergefor integrating changes from one branch to another. It is quite different frommergein thatmergecreates a new commit that has both parent branch commits as parents. Rebasing takes one set of commits from a branch and places them all at the end of the other branch.There are different reasons why you would want to use
mergeversusrebase. One of these reasons is thatrebaseleads to a cleaner history when working with many different branches and team members. -
Perhaps you decide that you want things to be how they were a certain number of commits ago. You can use
resetif you are absolutely sure that you don't want the last few commits.Resetis quite a nuanced command, so read carefully before attempting use. -
Revertallows you to reverse the changes introduced by certain commits by recording new commits to undo the changes. This is a safer option that simply throwing away past commits. But again, use this with caution. -
Cherry pickallows you to apply the changes introduced by some existing commits. For example, if you have two different branches, and your current branch lacks one or two commits that would be helpful but are only in the other branch, then you cancherry pickto grab those commits without merging or rebasing to get all the commits.
There are far more features and commands not mentioned here. Feel free to explore more and search for answers. There most likely exists a Git command for nearly everything you would want to do.
F. Remote Repositories
Thus far, we have worked with local repositories. We'll now discuss remote repositories, Git repos that are not on your own computer. They are on other machines, often servers of sites that host repos like GitHub or Bitbucket.
GitHub is a website service that can store your Git repositories. GitHub is not equivalent to Git. Rather, it is a convenient way to store your code online. It also has many features that make sharing and developing code collaboratively more simple and efficient.
For the rest of this lab, we'll be using GitHub in our examples. However, the same principles apply when using Bitbucket or other sites.
Private vs. Public Repos
By default, repositories on GitHub are public, rather than private. This means that anyone on the Internet can view the code in a public repo. For all class assignments, you are required to use private repositories.
Hosting school code in a public repo is a violation of the academic honesty policies of this class (and most other Berkeley EECS classes). Please keep this in mind when using sites like GitHub for collaboration.
You can request an education discount to get free private repos through GitHub Education. Bitbucket is also a great alternative to GitHub as it provides unlimited private code repos.
Adding Remotes
Adding a remote repository means that you are telling git where the repo is located. You do not necessarily have read/write access to every repo you can add. Actually accessing and modifying files in a remote is discussed later and relies on having added the remote.
$ git remote add [short-name] [remote-url]The remote URL will look something like https://github.com/berkeley-cs61b/skeleton.git
if you are using HTTP or git@github.com:berkeley-cs61b/skeleton.git if you are
using SSH.
By convention, the name of the primary remote is called origin (for original
remote repository). So either of the following two commands would allow me to
add the berkeley-cs61b/skeleton repository as a remote.
$ git remote add origin https://github.com/berkeley-cs61b/skeleton.git
$ git remote add origin git@github.com:berkeley-cs61b/skeleton.gitAfter adding a remote, all other commands use its associated short name.
Renaming, Deleting, & Listing Remotes
You can rename your remote by using this command:
$ git remote rename [old-name] [new-name]You can also remove a remote if you are no longer using it:
$ git remote rm [remote-name]To see what remotes you have, you can list them. The
-vflag tells you the URL of each remote (not just its name).$ git remote -v
You can read more about working with remotes in the Pro Git book.
Cloning a Remote
There are often remote repos with code that you would like to copy to your own computer. In these cases, you can easily download the entire repo with its commit history by cloning the remote:
$ git clone [remote-url]
$ git clone [remote-url] [directory-name]The top command will create a directory of the same name as the remote repo. The second command allows you to specify a different name for the copied repository.
When you clone a remote, the cloned remote because associated with your local
repo by the name origin. This is by default because the cloned remote was the
origin for your local repo.
Pushing Commits
You may wish to update the contents of a remote repo by adding some commits that
you made locally. You can do this by pushing your commits:
$ git push [remote-name] [remote-branch]Note that you will be pushing to the remote branch from the branch your HEAD
pointer is currently referencing. For example, let's say that I cloned a repo
then made some changes on the master branch. I can give the remote my local
changes with this command:
$ git push origin masterFetching & Pulling Commits
There are also times that you'd like to get some new commits from a remote that are not currently on your local repo. For example, you may have cloned a remote created by a partner and wish to get his/her newest changes. You can get those changes by fetching or pulling from the remote.
fetch: This is analogous to downloading the commits. It does not incorporate them into your own code.$ git fetch [remote-name]Why might you use this? Your partner may have created some changes that you'd like to review but keep separate from your own code. Fetching the changes will only update your local copy of the remote code but not merge the changes into your own code.
For a more particular example, let's say that your partner creates a new branch on the remote called
fixing-ai-heuristics. You can view that branch's commits with the following steps:$ git fetch origin $ git branch review-ai-fix origin/fixing-ai-heuristics $ git checkout review-ai-fixThe second command creates a new branch called
review-ai-fixthat tracks thefixing-ai-heuristicsbranch on theoriginremote.pull: This is equivalent to afetch + merge. Not only willpullfetch the most recent changes, it will also merge the changes into yourHEADbranch.$ git pull [remote-name] [remote-branch-name]Let's say that my boss partner has pushed some commits to the
masterbranch of our shared remote that fix our AI heuristics. I happen to know that it won't break my code, so I can just pull it and merge it into my own code right away.$ git pull origin master
G. Example: Remote Repository
For this follow-along example, you will need a partner. You will be working with your partner on a remote repository and have to deal with things like merge conflicts. Also note that both of you will need accounts on the same service, whether it be GitHub or Bitbucket.
Partner 1 will create a private repository on GitHub or Bitbucket and add Partner 2 as a collaborator. This repo can be called
learning-git.Note: GitHub Education discount requests take some time to process, so it is acceptable to use a public repo for just this lab. For all other assignments, you must use a private repo.
Also, please do not add your partner to your personal repo in the Berkeley-CS61B organization.
Partner 2 will create a
READMEfile, commit the file, and push this commit to thelearning-gitremote.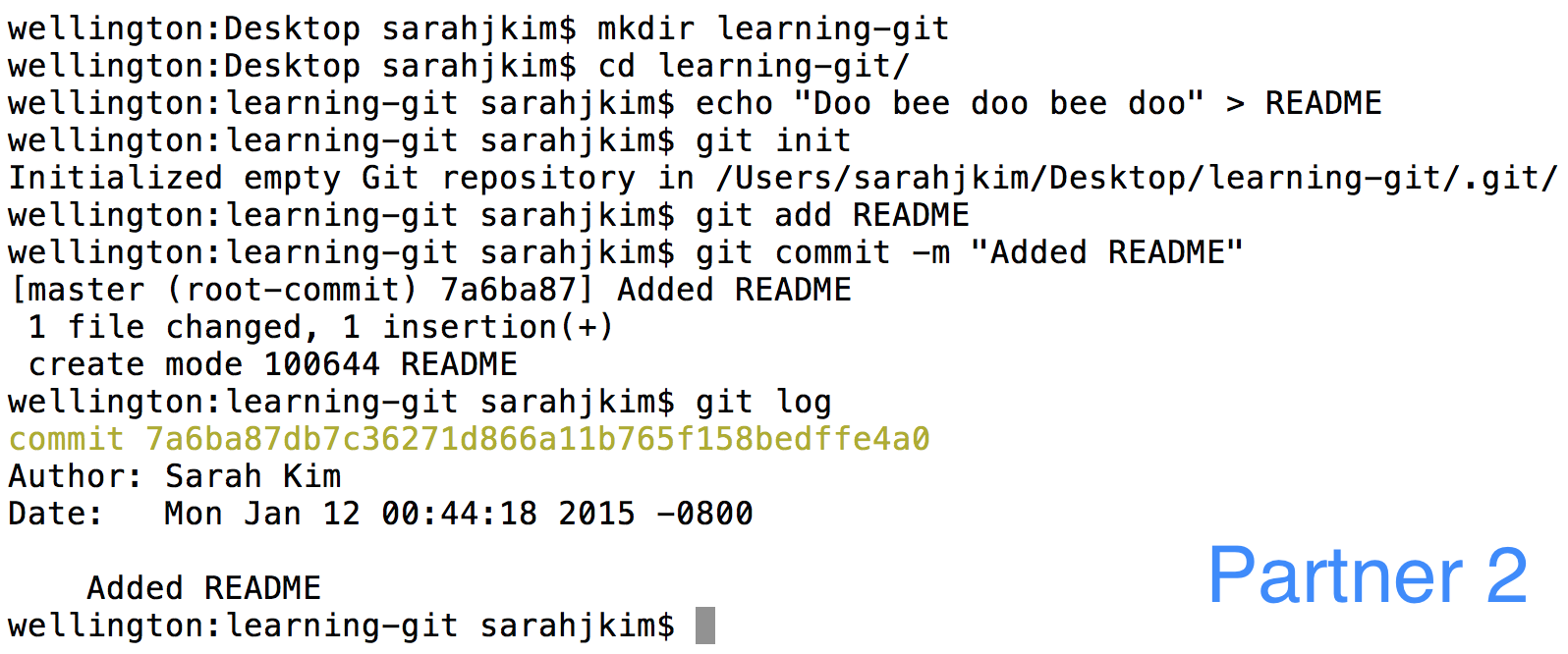
Partner 2 will also add the remote that Partner 1 created and push this new commit.
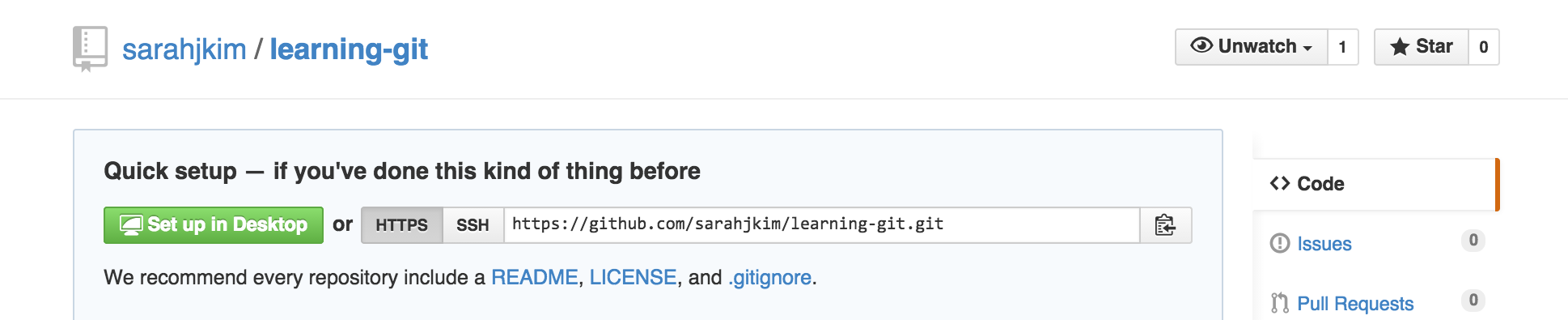
With either GitHub or Bitbucket, you can find the remote URL on the repo's main page.
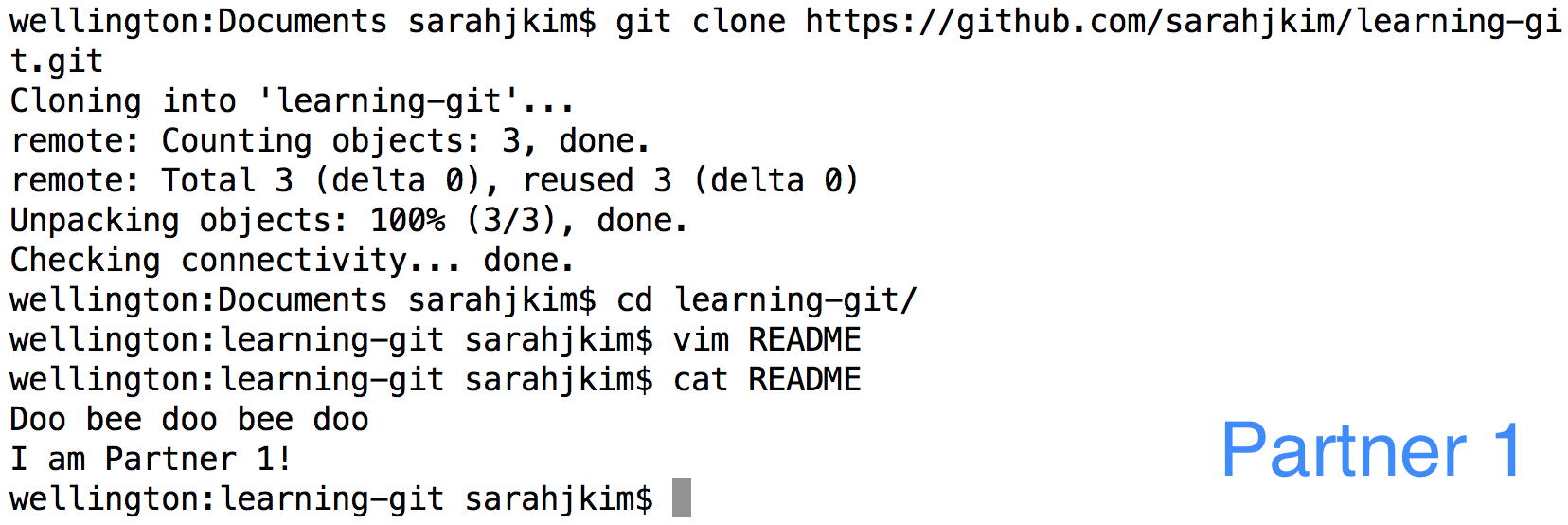
Partner 1 will now clone the remote repo to their own machine then add a line to the bottom of README. (Note: At this point, the pictures may get a bit confusing because I'm pretending to be both partners.)
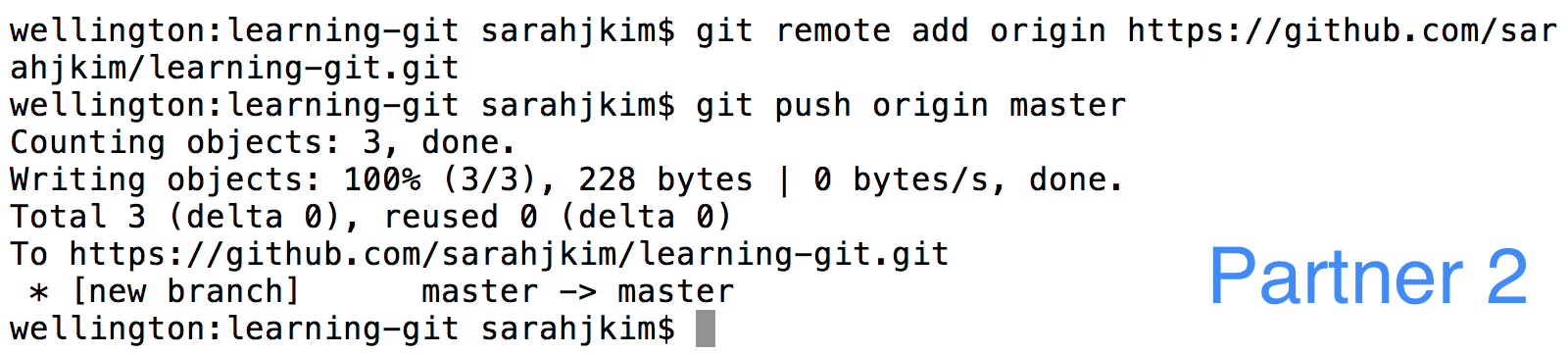
Partner 1 will commit this change and push it back to the remote.
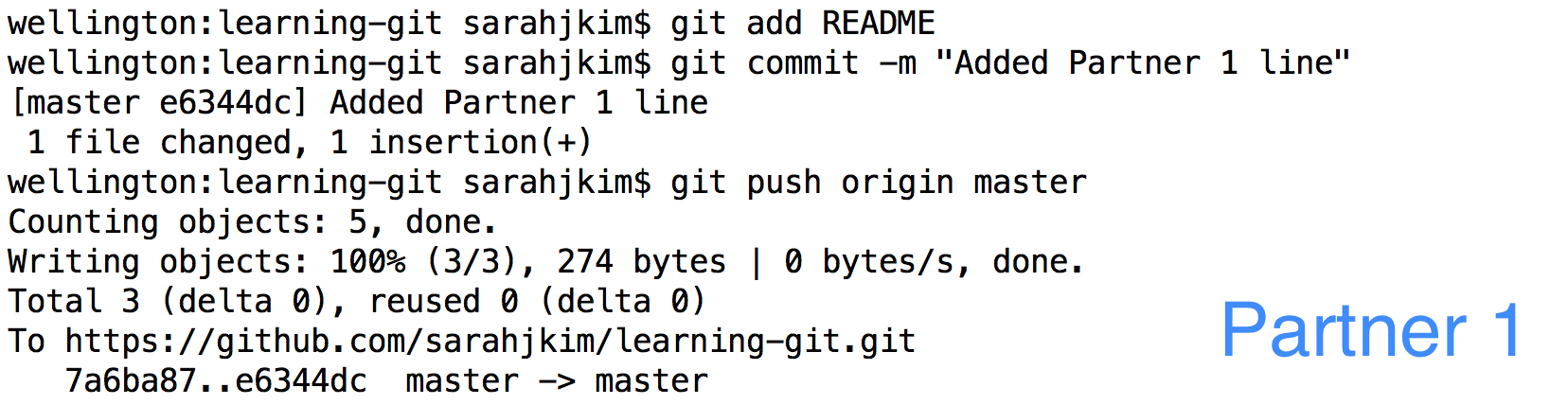
Partner 2 will similarly add a line to the bottom of their README and commit this change.
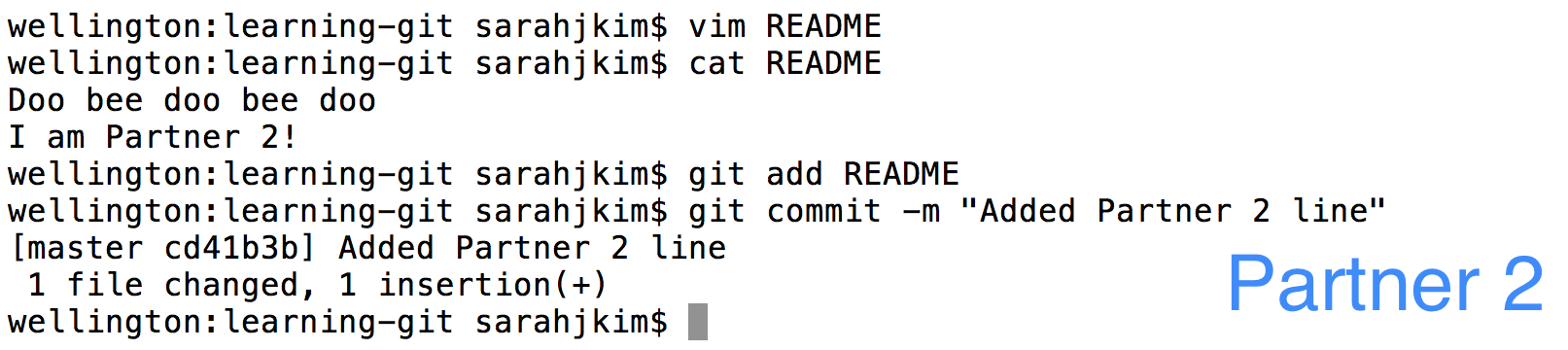
Partner 2 will now pull and find that there are merge conflicts.

Partner 2 should resolve the merge conflicts by rearranging the lines. Then Partner 2 should add
READMEand commit and push to finish.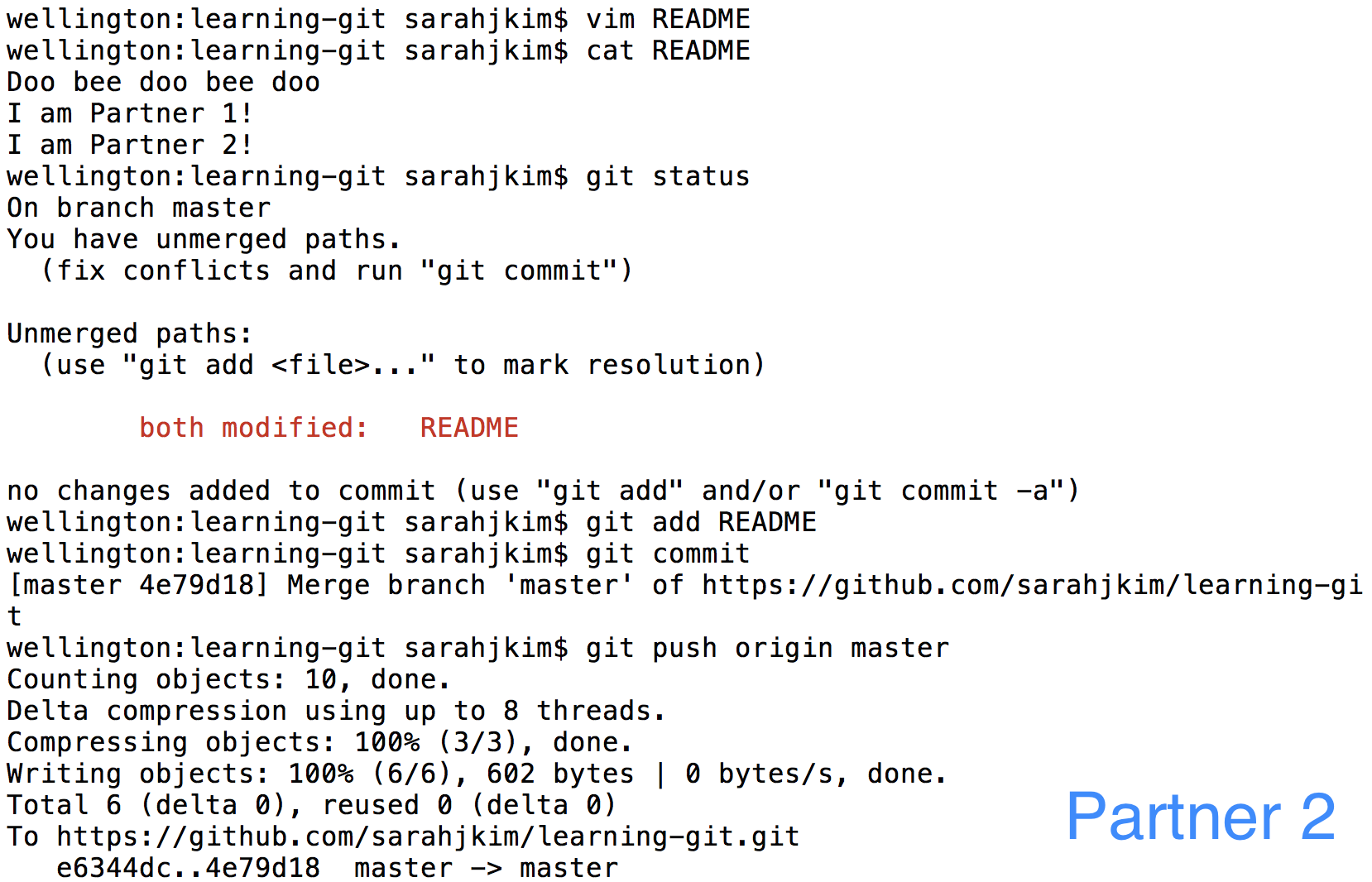
Partner 1 can now pull and get two new commits - the added line & the merge commit. Now both partners are up to date.
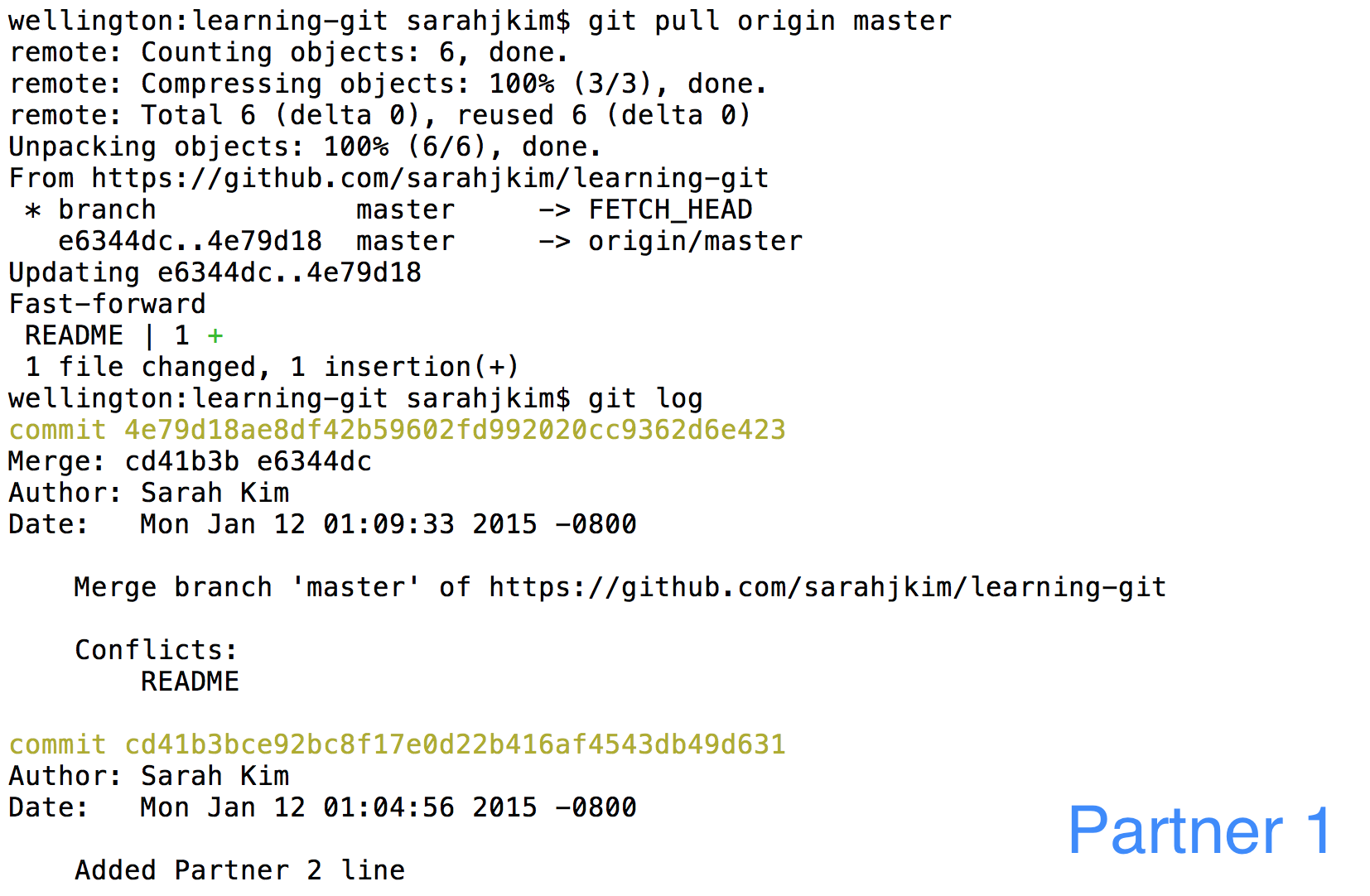
H. Conclusion
More with Remotes
These simple commands to add/remove remotes, push commits, and fetch/pull changes can be combined with all the commands you've learned in regards to local repositories to give you a powerful toolkit in working collaboratively with others.
GitHub has some other really cool features that can be helpful for in project development:
Extra Reading
For those of you who found this topic interesting, check out these extra resources! Keep in mind, however, that the best way to learn to use Git effectively is to just start incorporating it into your own coding workflow! Good luck, and have an octotastic day!
- Git Documentation is really quite good and clear, and there is a great Pro Git book by Scott Chacon.
- Hacker's Guide to Git is a very friendly introduction to how Git works. It gives a peek at the structure of commits & branches and explains how some commands work.
- Learn Git Branching is a fun and interactive tutorial that visualizes Git commands.
I. Advanced Git Features
Here are some more advanced features that might make your life a little easier. Once you get the hang of the basic features of git, you'll start to notice some common tasks are a bit tedious. Here are some built-in features that you might consider using.
Rebasing
Git is all about collaborative programming, so more often than not, you'll find yourself dealing with merge-conflicts. In most cases, the changes you've made are separated from the conflicting commits such that you can just put your commit right on top of all the new commits. However, git will merge the two versions and add an extra commit letting you know that you merged. This is pretty annoying and leads to a pretty messy commit history. This is where the magic of rebasing comes into play.
When you push changes onto Github and the remote copy has been modified, you'll be asked to pull in the changes. This is where you usually get a merge-conflict. Instead, pull with the rebase flag:
$ git pull --rebase origin masterIt's as simple as that! The changes from the server will be applied onto your working copy and your commit will be stacked on top.
Squashing Commits
You might find yourself in a situation where you've created many small commits with tiny related changes that could really be stored in a single commit. Here, you'll want to squash your commits using the rebase command. Suppose you have four commits that I want to combine. You would enter the following:
$ git rebase -i HEAD~4From here, you would be prompted to pick a commit to collapse the other commits into, and pick which commits should be combined:
pick 01d1124 Adding license
pick 6340aaa Moving license into its own file
pick ebfd367 Jekyll has become self-aware.
pick 30e0ccb Changed the tagline in the binary, too.
# Rebase 60709da..30e0ccb onto 60709da
#
# Commands:
# p, pick = use commit
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
#
# If you remove a line here THAT COMMIT WILL BE LOST.
# However, if you remove everything, the rebase will be aborted.
#It's best to pick the topmost commit and squash the rest into it. You can do this by changing the text file to this:
pick 01d1124 Adding license
squash 6340aaa Moving license into its own file
squash ebfd367 Jekyll has become self-aware.
squash 30e0ccb Changed the tagline in the binary, too.
# Rebase 60709da..30e0ccb onto 60709da
#
# Commands:
# p, pick = use commit
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
#
# If you remove a line here THAT COMMIT WILL BE LOST.
# However, if you remove everything, the rebase will be aborted.
#Voila! All those tiny commits have collapsed into a single commit and you have a cleaner log file.